Executive Summary
"Jira-driven delivery" can be defined as a mode of execution in which the primary unit of planning, coordination, and reporting is the ticket: epic, story, task, bug, or subtask. In current Jira documentation, work items are individual pieces of work; stories are user-perspective requirements; epics are larger bodies of work; and subtasks further decompose execution. That model emerged from the fusion of plan-driven lifecycle control, Agile decomposition, and issue-tracking platforms. It worked because large software programs once needed visible queues, roles separation, documentation baselines, and archival audit trails to coordinate many specialists across long release cycles. We argue, however, that the same decomposition now often fragments business intent, weakens context, increases handoffs, and slows learning. In an AI-enabled environment, the scarce resource is no longer only coding effort; it is faithful translation from business intent into verifiable, production-ready capability (Atlassian, 2025; Atlassian, 2026; DORA 2025; Hou et al., 2024).

A more suitable model is intent management: structured capture of objectives, outcomes, rules, constraints, decisions, and acceptance criteria, maintained as living artifacts that can directly guide design, testing, deployment, and revision. This does not eliminate Jira; rather, it demotes tickets from "system of truth" to execution interface. The practical shift is not toward less rigor, but toward different rigor: fewer intermediate documents, more explicity traceability, more executable requirements, smaller batches, and tighter feedback loops. Recent research shows that AI amplifies existing organizational strengths and weaknesses, while empirical studies on AI-assisted coding and AI-generated test specifications show meaningful gains only when context, verification, and human oversight remain strong (DORA, 2025 Peng et al., 2023; Murali et al., 2024; Milchevski et al. 2025; NIST, 2023).
From lifecycle control to ticket-based delivery:
Jira-driven delivery is best understood as a ticket-based extension of the modern SDLC. In Atlassian documentation, Jira work items track bugs and individual pieces of work; epics represent larger bodies of work; stories express requirements from the user's perspective; and subtasks break work down further. User stories are intentionally concise and informal: Atlassian describes them as small, user-focused units that explain the "why" of work, with details added later through conversation and confirmation. Ticket-based delivery therefore assumes that business intent can be sliced into units small enough to estimate, assign, implement, and close (Atlassian, 2025; Atlassian, 2026).
The deeper lineage is older. Winston Royce described a sequential implementation scheme for large software in 1970, arguing that large customer-facing systems required requirements analysis, design, coding, testing, and operational baselines. Although Royce explicitly warned that a purely single-pass implementation was "risky and invites failure", later practice institutionalized document-driven control through standards and process frameworks such as United States Department of Defense DoD-STD-2167A, IEEE 830, and the Software Engineering Institute Capability Maturity Model. These frameworks made sense in an era of expensive releases, heavyweight contracting, and large specialist teams: explicit documentation, reviews, and process discipline improved predictability, auditability, and cost/schedule control (Royce, 1970; DoD, 1988; IEEE, 1998; Paulk et al., 1993).
Ticketing systems digitized that work queue. The Bugzilla project records that Bugzilla was first publicly deployed in 1998 as a web-based bug system to replace Netscape's in-house tracker. Jira followed in 2002; Atlassian later recalled that its founders built Jira because the bug tracker they were using "wasn't that great," and Jira subsequently expanded from software issue tracking into generalized work management. Ticket-based delivery therefore grew from a historically rational stack: formal lifecycle governance above, agile decomposition in the middle, and issue tracking at the execution layer (Bugzilla Project, 2023l Atlassian, 2022; Atlassian, 2020).
Why it Worked:
Ticket-based delivery solved a real coordination problem. Bertram et al. found that issue trackers function not merely as databases, but as "outboard brain," communication hub, knowledge repository, and coordination channel for managers, developers, testers, and customers. In a large Microsoft study, bug tracking systems similarly served as central hubs of coordination and organizational memory, while reassignment helped route work toward the best person able to fix it. In other words, tickets were valuable because people, not code generation, were the scarce integrating mechanism, and the software organization needed a durable place to synchronize distributed human work (Bertram et al., 2010; Guo et al., 2011).
Agile user stories strengthened this model for a time. The Agile Manifesto privileged individuals and interactions over process and tools, working software over comprehensive documentation, and responding to change over following a plan. Scrum, developed in the early 1990s, organized work around evolving backlogs, goals, and increments. Empirically, Lucassen et al. found that practitioners often perceived user stories, story templates, and quality guidelines as improving productivity and the quality of work deliverables. When teams were near the domain and the story's "card, conversation, confirmation" triad remained intact, concise stories were an efficient compression of user intent (Manifesto Authors, 2001; Schwaber & Sutherland, 2020; Lucassen et al., 2016; Atlassian, 2026).
Why ticket-based delivery is increasingly inadequate:
The problem today is not Jira as a tool; it is Jira as the primary representation of business truth. Aranda and Venolia showed that even simple bug histories depend on social, organizational, and technical knowledge that cannot be reliably extracted from repositories alone; the repository view is often incomplete and sometimes erroneous. Baysal et al. found that issue trackers create information overload and irrelevant signal, causing issues to be "dropped on the floor." Guo et al. showed that repeated bug reassignments arise from ownership ambiguity, poor report quality, uncertainty about root cause, and workload balancing. Ticket systems compartmentalize work efficiently, but they also compartmentalize meaning (Aranda & Venolia, 2009; Baysal et al., 2015; Guo et al., 2011).
This weakness is especially acute for requirements. Atlassian explicitly notes that user stories are not detailed requirements; they are informal and rely on later discussion. Park and Maurer showed why that becomes fragile at scale: stories capture a business perspective, but developers and testers often need more explicit detail; without linkable traceability, story cards can become outdated and forgotten. The requirements-traceability literature reports familiar problems: insufficient resources, weak coordination across related artifacts, limited contextual information for decision-making, and high cost of manual traceability maintenance. When business intent is broken across epics, stories, acceptance criteria, test cases, code branches, and release records, governance becomes retrospective bookkeeping rather than embedded control (Atlassian, 2026; Park & Maurer, 2008; Torkar et al., 2012; IEEE, 1998).
The speed mismatch is now decisive. DORA argues that traditional phased handoffs impose large fixed costs, delay feedback for weeks or months, and underperform cross-functional, small-batch flows. Its 2025 AI research further concludes that AI is an amplifier, not a silver bullet. In parallel, Hou et al.'s large review of LLM use in software engineering shows growing application across requirements engineering, specification generation, traceability, design, testing, and repair, but also highlights ambiguity, data dependency, trustworthiness, and context sensitivity as major challenges. Put differently: AI can compress execution, but only if intent is structured well enough to survive compression (DORA, 2025; Hou et al., 2024).
The contrast is illustrated below. The left-hand flow shows how intent is progressively translated into tickets and then handed off; the right-hand flow shows how structured intent can remain continuous across design, test, deployment, and feedback. The claim is not that all tickets disappear, but that tickets cease to be the canonical representation of value, constraints, and correctness (Atlassian, 2026; DORA, 2025).
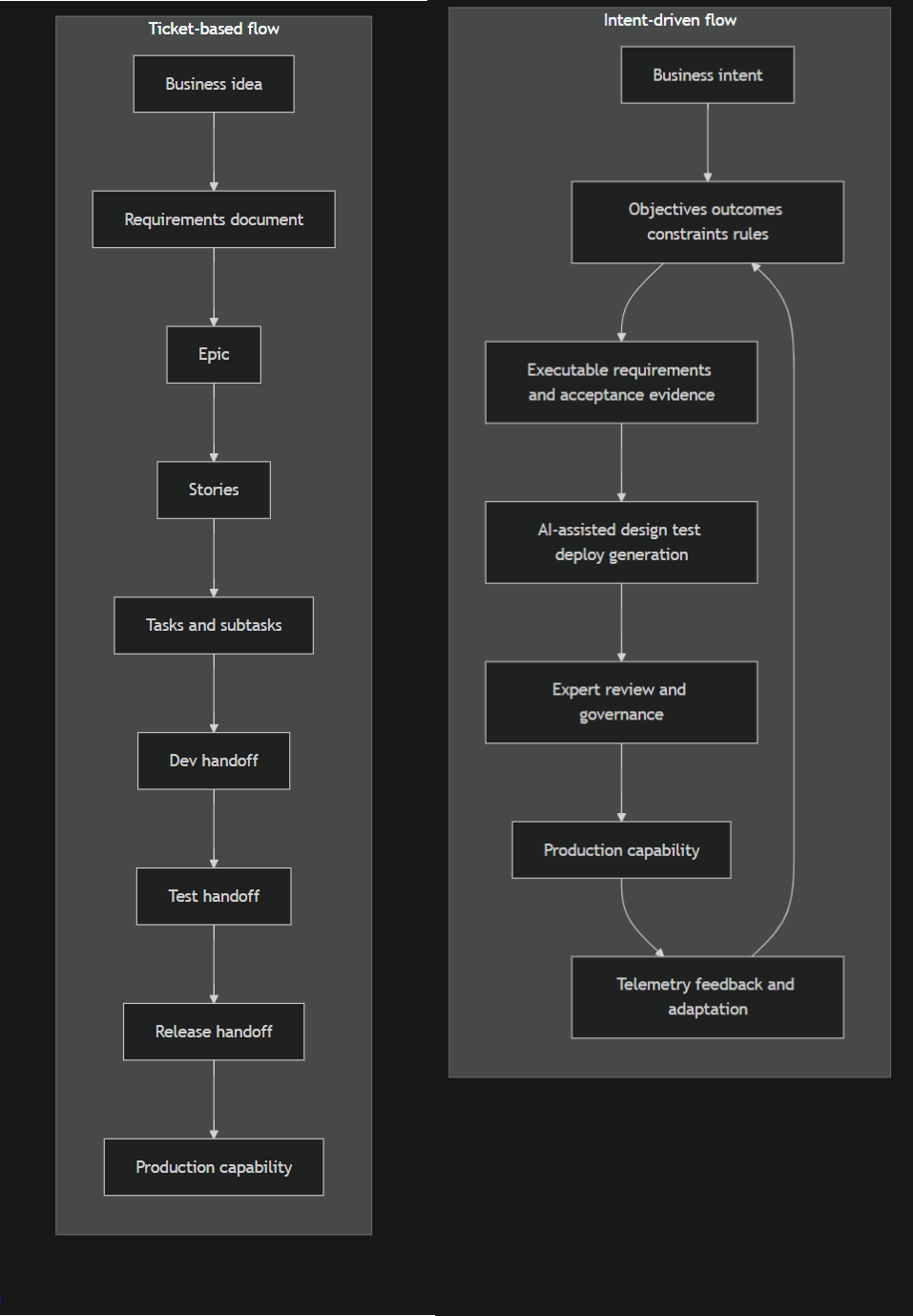
The emerging alternative is intent management. Here the primary artifact is not the ticket but a structured intent model containing objectives, outcomes measures, stakeholders, rules, constraints, terminology, decisions, and acceptance evidence. Scrum already points in this direction: the Product Goal is the long-term objective, and "the rest of the Product Backlog emerges" to define what fulfills it. IEEE 830 likewise required that a good requirements specification be verifiable, modifiable, and traceable, and that customer and supplier prepare it jointly. Reduced documentation, in this sense, does not mean less precision; it means fewer dead intermediary documents and more authoritative, linked, machine-usable artifacts (Schwaber & Sutherland, 2020; IEEE 1998).
Executable requirements are central to that shift. Park and Maurer argue that linking user stories to executable acceptance tests is critical because tests make requirements explicit, reduce ambiguity through concrete examples, and provide measurable progress. Their later case work on executable acceptance test-driven development showed that such specifications can be readable and writable by domain experts together with the development team. This aligns with classic requirements guidance: if a requirement is not verifiable, it should be revised or removed. In an intent-managed model, acceptance logic and business rules belong inside the requirements expression itself, not as downstream afterthoughts (Park & Maurer, 2008; Park & Maurer, 2009; IEEE, 1998).
AI then becomes a translation and acceleration layer. Hou et al. document LLM use in requirements analysis, elicitation, specification generation, traceability, design, verification, testing, and repair. Bosch researchers reported a 30-40% reduction in effort for deriving system-level test specifications from requirements by combining LLMs with structured intermediate artifacts and expert review. Peng et al. found that developers with GitHub Copilot completed an experimental task 55.8% faster, while Murali et al. reported that Meta's Code Compose serviced 16,000 developers and accounted for 8% of changed code, in part by surfacing internal knowledge at the point of work. Yet the same literature stresses ambiguity, privacy, and trust risks; human review and domain grounding therefore remain indispensable (Hou et al., 2024; Milchevski et al., 2025; Peng et al., 2023; Murali et al., 2024; NIST, 2023).
How Requirementum QGR operationalizes intent management:
Requirementum QGR's model can be read as an applied implementation of intent management. Senior analysts own the translation layer from business intent to delivery-ready structure: they elicit objectives, define capabilities and outcomes, map processes, rules, exceptions, and constraints, assign traceable identifiers, and express acceptance logic in a form AI tools can use. Domain experts provide the operational truth that generic software teams and generic models lack: vocabulary, policy nuance, edge cases, real workflows, and the business meaning of "correct." AI tools then accelerate the production of candidate artifacts, requirements refinements, scenario sets, test suites, interface drafts, API contracts, deployment assets, and traceability links, which analysts and experts review, correct, and authorize. That pattern is consistent with IEEE's requirement for joint preparation of requirements, with executable-specification research, and with recent AI-assisted requirements-to-test evidence (IEEE, 1998; Park & Maurer, 2009; Milchevski et al., 2015).
Operationally, the model shortens the path from idea to production by replacing the long relay race of ticket decomposition with a tighter artifact chain: intent brief, capability definition, rule and decision catalog, executable acceptance evidence, generated design/test/deployment assets, and production telemetry. Governance is embedded rather than appended. Each capability element is linked backward to goals and constraints, and forward to tests, code, releases, and operational evidence. Small-batch release discipline and DORA-style metrics - lead time, deployment frequency, failed deployment recovery time, and change failure rate, measure whether intent is reaching production safely and quickly. The expected benefits are fewer clarification loops, fewer harmful reassignments, lower context loss, faster specification and test production, and better auditable traceability across the delivery path (DORA, 2025; Guo et al., 2011; Milchevski et al., 2025).
Implications, risks, and recommended next steps
The organizational implication is not that Jira disappears, but that its role changes. Ticketing systems remain useful for queues, workflow visibility, and operational tracking, yet they should no longer be treated as the canonical model of business intent. Organizations should pilot an intent-managed flow on one bounded capability, define a common schema for goals, rules, constraints, and acceptance evidence, and connect that schema to AI-assisted generation and automated verification. The first practical gains are likely to appear in requirements clarification, test-specification generation, acceptance automation, and traceability recovery rather than in fully autonomous coding (DORA, 2025; Milchevski et al., 2025; Hou et al., 2024).
Risks remain substantial. NIST warns that AI complicates risk management, particularly when third-party software and data are involved, and recent software-engineering surveys identify data dependency, ambiguity, privacy leakage, limited interpretability, and context-specific failure as material constraints. For that reason, the "end of Jira-driven delivery" should not be read as an invitation to remove control. It is, rather, an argument for moving control upstream, closer to intent, so that AI accelerates a disciplined, traceable, expert-guided system of delivery instead of merely manufacturing tickets faster. Jira may remain in the workflow; what ends is its status as the primary container for truth (NIST, 2023; Hou et al., 2024; DORA, 2025).
REFERENCES:
Aranda, J., & Venolia, G. (2009). The Secret Life of Bugs: Going Past the Errors and Omissions in Software Repositories.
Atlassian. (2022). 20 years of Atlassian, 20 lessons learned.
Atlassian. (2025–2026). Jira work items overview; What are work types?; Epics, Stories, and Initiatives; User Stories with Examples and a Template.
Baysal, O., Holmes, R., & Godfrey, M. W. (2014). No Issue Left Behind: Reducing Information Overload in Issue Tracking.
Bertram, D., Voida, A., Greenberg, S., & Walker, R. (2010). Communication, Collaboration, and Bugs: The Social Nature of Issue Tracking in Small, Collocated Teams.
Bugzilla Project. (2023). Bugzilla Celebrates 25 Years; About: A Brief History of Bugzilla.
DORA. (2025–2026). State of AI-assisted Software Development; Working in Small Batches; DORA’s Software Delivery Performance Metrics.
Guo, P. J., Zimmermann, T., Nagappan, N., & Murphy, B. (2011). “Not My Bug!” and Other Reasons for Software Bug Report Reassignments.
Hou, X., Zhao, Y., Liu, Y., et al. (2024). Large Language Models for Software Engineering: A Systematic Literature Review.
IEEE. (1998). IEEE Recommended Practice for Software Requirements Specifications (IEEE 830-1998).
Lucassen, G., Dalpiaz, F., van der Werf, J. M. E. M., & Brinkkemper, S. (2016). The Use and Effectiveness of User Stories in Practice.
Milchevski, D., Frank, G., Hätty, A., et al. (2025). Multi-Step Generation of Test Specifications using Large Language Models for System-Level Requirements.
Murali, V., Maddila, C., Ahmad, I., et al. (2024). AI-assisted Code Authoring at Scale.
NIST. (2023). Artificial Intelligence Risk Management Framework 1.0.
Paulk, M. C., Curtis, B., Chrissis, M. B., & Weber, C. V. (1993). Capability Maturity Model for Software, Version 1.1.
Peng, S., Kalliamvakou, E., Cihon, P., & Demirer, M. (2023). The Impact of AI on Developer Productivity: Evidence from GitHub Copilot.
Royce, W. W. (1970). Managing the Development of Large Software Systems.
Schwaber, K., & Sutherland, J. (2020). The Scrum Guide.
The Agile Manifesto Authors. (2001). Manifesto for Agile Software Development.